
Why estimate?
Published August 27, 2018
Why estimate?
By Katherine Leach-Kemon and Julia Gall
We’ve talked a little bit about the more than 90,000 data sources that we use in the Global Burden of Disease. And we’ve explored some of the ways that we work to make sure these sources speak the same language. But we haven’t yet answered a question we get asked frequently: Why? Why do all of this work for estimates instead of simply presenting the data points?
The answer has a bit to do with the “strength in numbers” of all of the sources that we use, a bit to do with the work that goes in to making these sources – and diseases – comparable, and a lot do with getting a more accurate picture of population health around the world.
In short, without estimation, we wouldn’t have the GBD.
Many widely used numbers, ranging from gross domestic product (GDP) to weather forecasts, use estimation techniques to provide the best information possible. In the case of GBD, statistical estimation techniques make it possible to identify the most burdensome diseases, injuries, and risk factors in 195 countries and territories worldwide; to compare diseases that kill to diseases that cause poor health; and to begin to estimate the toll of diseases, injuries, and risk factors that may be little understood. This ability to explore and compare is an essential part of what makes GBD a powerful tool for policymaking and priority-setting, used by many governments and organizations around the world to make people healthier.
The myth of “perfect” data
Intuitively, it might seem that raw data – e.g., the results of a census or the findings of a study – are the “truth,” and that any estimation process only serves to adulterate these raw data.
Unfortunately, in practice there is no such thing as “perfect” data. We explored some of the issues with data inputs in our last two posts but want to delve into some other examples here as well – the ways that data can be challenging to interpret or compare are myriad. With imperfect data, the best we can do to try to get as close to the “truth” as possible is compile different data sources and studies, then evaluate them to see what story they are telling us.
Take, for example, our efforts to estimate alcohol use in the United States. When survey respondents are asked how many drinks they consume per day on average, we know that they typically underreport their consumption. We know this since researchers have documented that alcohol sales in the US exceed the amount that people report consuming in surveys. So we have to adjust the data to correct for this underreporting using statistical estimation techniques.
In another example, in a war zone, it can be challenging to measure health outcomes such as child mortality. In an area with ongoing armed conflict, we compared different surveys on child mortality, which revealed that one survey had a much lower estimate of child mortality than the others did. So which data sources should we believe?
Upon further investigation and consultation with our collaborators, we learned that the survey with the lower estimates of child mortality was conducted in safer areas of the country and therefore underestimated how many children died. So we concluded that the data sources showing higher estimates were more accurate.
You can begin to see why it can be challenging to rely on just one source, and why it is so important to consider various sources as you work toward comprehensive estimates.
When data are high-quality, GBD estimates tend to mirror them
All of this is not to say that data are not important – data are key, and it is important to keep in mind that when raw data are high-quality, the GBD estimates we produce tend to align with them. For example, the graph shows how road injury mortality estimates for Brazil (blue solid line) align closely with the vital registration data (yellow dots) for many years. High-quality data boost the strength of GBD estimates.
Brazil road injury mortality estimates and raw data (deaths per 100,000), all ages, both sexes, 1980–2016
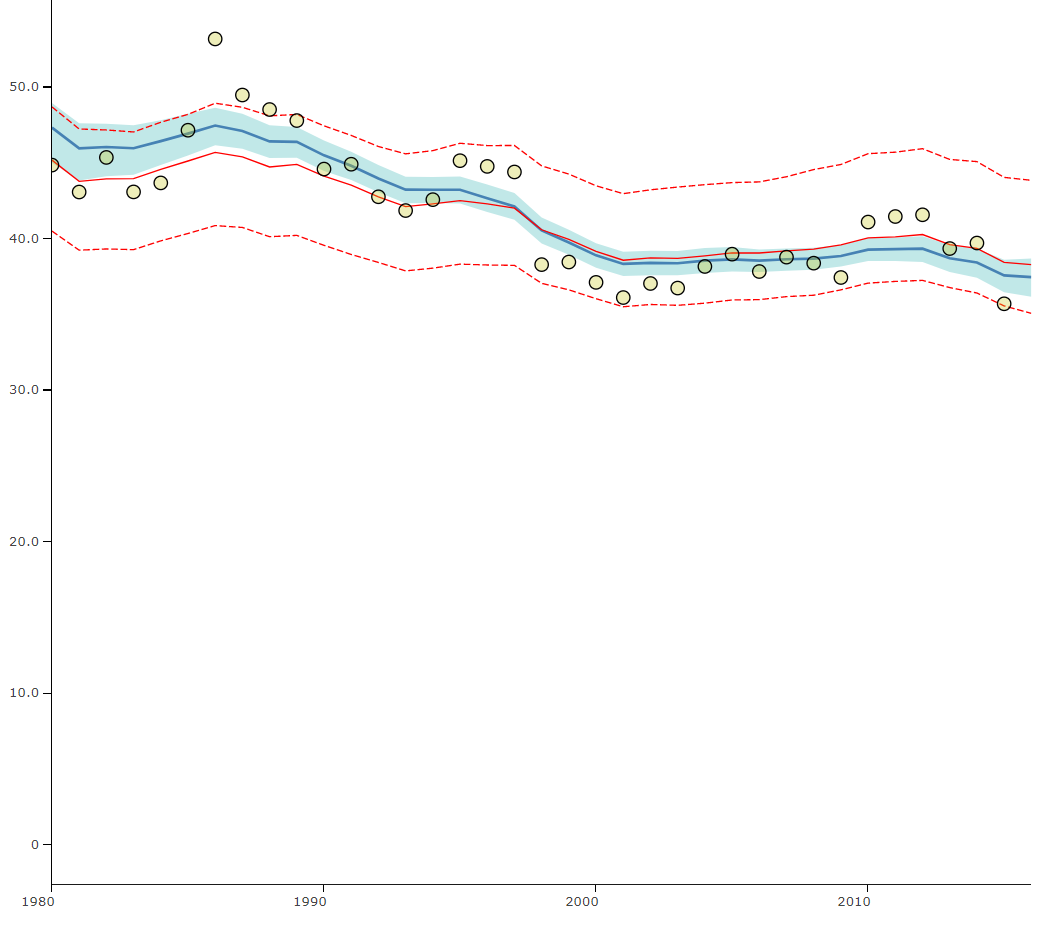

Yellow dots indicate vital registration data points for road injury mortality in Brazil, while the solid blue line indicates the GBD estimates for road injury mortality in that country.
Without estimates, there would be no GBD
Without estimation, you wouldn’t be able to use the GBD to answer questions such as:
- What causes more disease burden in my country – cancer or mental disorders?
- What are the dominant health problems among older and younger people in my country?
- How has burden of disease in my country changed over time?
- How is my country doing compared to its neighbors?
Estimation techniques are essential for measuring burden of disease. Since raw data are not perfect and can’t give us a complete or comparable picture of health worldwide, estimates are a useful tool for helping decision-makers develop a better understanding of health trends in their country, their region, and the world.
Our next post will explore some of how we calculate GBD estimates from all of the cleaned data sources.
This post is part of the IHME Foundations series, which discusses some of the core aspects of IHME’s work while exploring along the way everything from how you manage over 50 databases with more than 39 billion rows (and what that even means) to how you help governments in Central America evaluate the impact of their health programs. Join us for the whole series here, or on Medium.