
How we collect data
Primary data collection helps to fill critical information gaps for decision-making and serves to strengthen existing health information systems.
As a research institute, we rely primarily on data collected by others, or secondary data. We work with a vast network of scientists, government officials, and medical professionals to help us create the most accurate disease and mortality estimates in the world. For some projects, we also conduct primary research with field partners across the globe.
What is our primary data collection process?
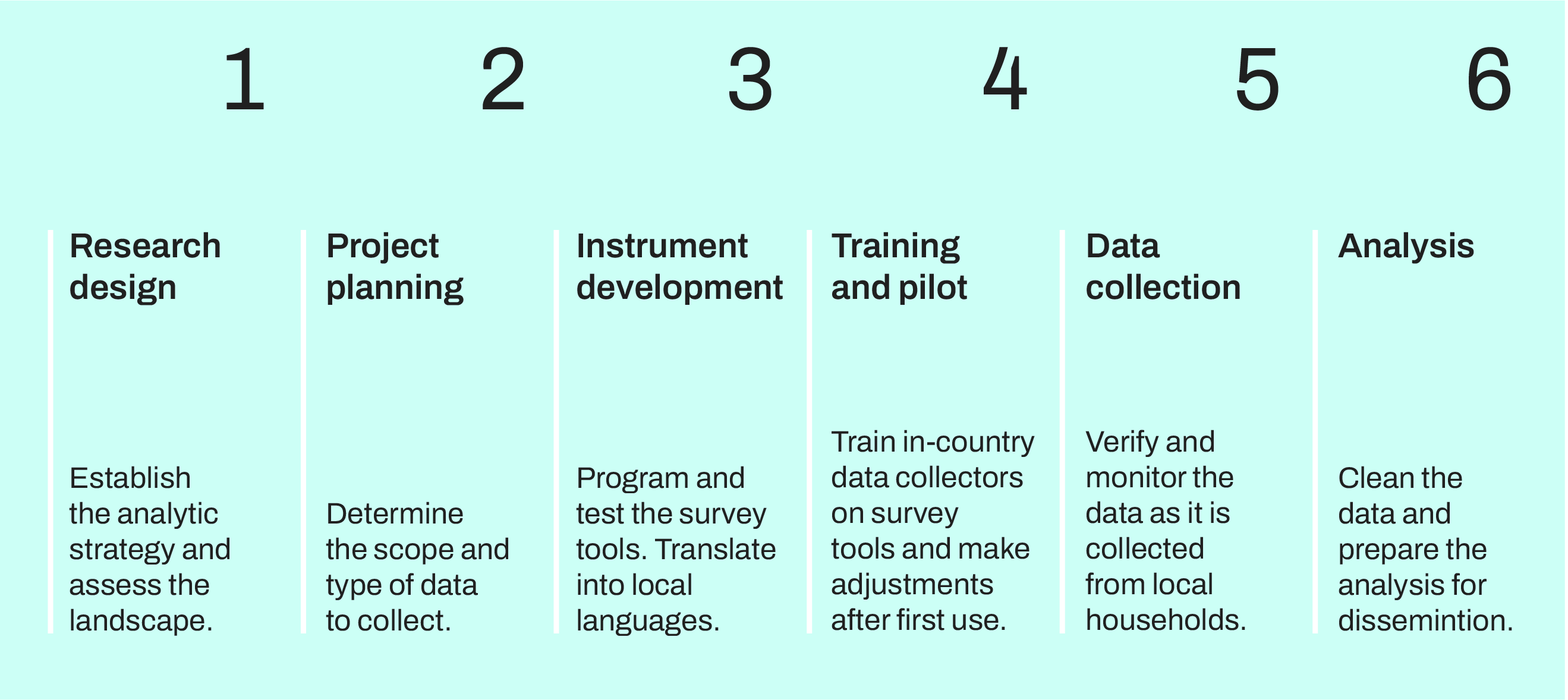
Overview
The majority of our projects use data collected by other research organizations, often gathered or obtained by the extensive Global Burden of Disease (GBD) Collaborator Network.
However, we do conduct primary data collection as a component of many research projects.
- We develop the instruments, protocols, and sampling methodology with stakeholders, and we rely on the expertise of in-country partners and data collectors to carry out this work.
- We conduct quantitative data collection, including household, health facility, medical records, verbal autopsy, and biometric data.
- We publish primary data on the IHME data page in the Global Health Data Exchange (GHDx), our data catalog, along with survey instruments, data dictionaries, protocols, and summary information.
Censuses and household interviews
We collect household survey data capturing information like use, access, expenditure, and perceived quality of treatment for specific medical conditions.
Medical record reviews
We extract information on record keeping and quality of health care, as measured against the norms in each country, from medical records.
Verbal autopsies
We use questionnaires to collect information about the signs, symptoms, and demographic characteristics of a recently deceased person from someone familiar with the deceased, in order to determine the individual’s cause of death.
Biometric data captured in households
We take measurements in select households, such as height, weight, anemia measurements, and vaccine antibodies.
Health facility observation and interviews
We record the availability of key interventions, supplies, equipment, infrastructure, staff, and good management practices in clinics, hospitals, and other health facilities.
What is our secondary data collection process?
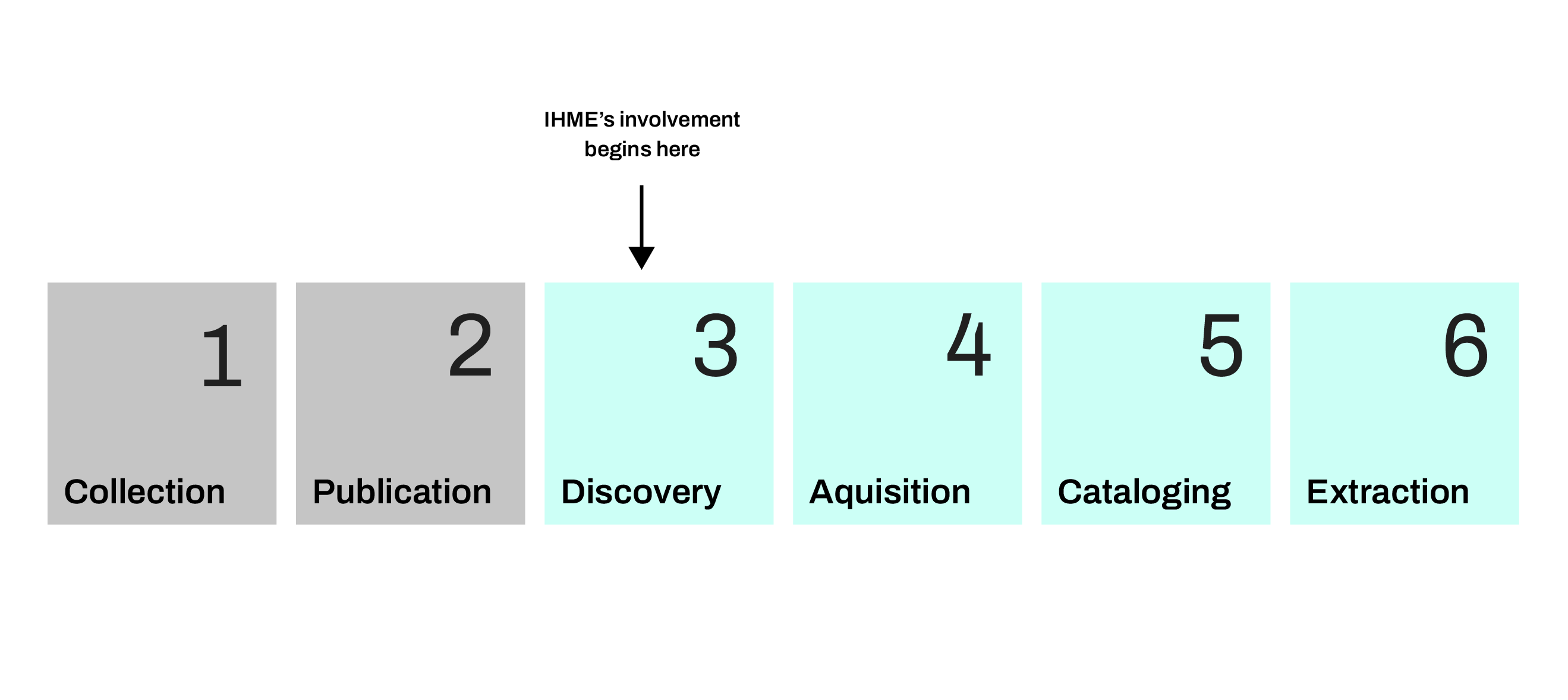
How do we use secondary data in research estimates?
Outside organizations are creating data
Step 1: Data collection
Private and public organizations around the world collect data through surveys, censuses, and other methods.
Step 2: Data publication
Organizations publish the data they have collected and share details on the methodology. Depending on the nature of the data, they may be publicly available for anyone to download, or they may require a special permission to access.
We get involved
Step 3: Data discovery
Our data librarians conduct internet searches, review government and international agency websites, monitor known data sources, and consult with international partners to discover new datasets when they are published.
Step 4: Data acquisition
If a newly discovered dataset is publicly available, we download it straight from the source. If not, we request access to the data, which may involve entering into a data use agreement with the collector.
Step 5: Data cataloging
Data librarians create a record in the GHDx, our data catalog, to document each dataset we acquire and all the information we have about it, like the location, timeframe, collecting organization, and more. See for example, the Mozambique Demographic and Health Survey 1997.
Step 6: Data extraction and transformation
Researchers extract data and run them through modeling tools, turning them from individual data points into regional estimates.
Step 7: Estimate publication
Through research projects like the Global Burden of Disease (GBD), we publish our estimates alongside peer-reviewed publications. All our estimates from GBD are available to download through the GBD Results Tool.
What secondary data do we use?
We produce research aimed at illuminating the state of health everywhere, including estimates of the Global Burden of Disease (GBD), health financing, and future health scenarios.
- The first step in producing those results is acquiring source data, which is then cleaned, transformed, and run through mathematical models in order to create our final estimates.
- Our models use input data from over 200 countries and territories, gathered from hospitals, governments, and other partner organizations.
Datasets are all cataloged in the GHDx and fall into several categories, including, but not limited to:
Administrative data
Data from the records maintained by agencies, institutions, commercial entities, and governments, where the data are used for administrative purposes or for providing services. Examples include hospital and other health facility data, claims data, occupational injuries data, and police data.
Census
Data from a complete count of a specified population or entity; this may include information about behavior, opinions, or characteristics based on responses to questions.
Demographic surveillance
Data from a system to monitor vital events and migration in a specific population over time (generally subnational). Differs from vital registration in that it may include other data points or data collection methods such as surveys.
Disease registry
We take measurements in select households, such as height, weight, anemia measurements, and vaccine antibodies.
Environmental monitoring
Data from measurement systems that capture information about the climate and the environment.
Survey
Data about behavior, opinions, or characteristics based on responses to questions from a sample of a specified population or entity.
Vital registration
Data from a system that registers vital events in a population, including births, stillbirths, deaths, marriages and divorces – a specific type of administrative data from hospitals and other health facilities.
Primary and secondary data in our data catalog
Browse our data records by the types of information you need.